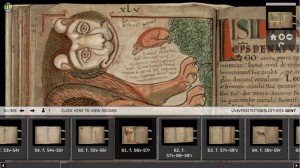
Guest Post by Marie Svoboda, J. Paul Getty Museum Mummy Portrait of a Young WomanTempera on wood, about A.D. 170–200 In 2013, the Antiquities Conservation Department at the J. Paul Getty Museum launched a collaborative study inviting major museums around the world to participate in the study and characterization of the manufacturing practices and material […]
Read More… from Image Comparison of Ancient Mummy Portraits: The Appear Project